Running Spark on Kubernetes
翻译自官网Running Spark on Kubernetes,仅供参考。
spark可以运行在kubernetes集群上,这个特性需要kubernetes的调度器已经添加了spark。
现在kubernetes的调度器还在实验阶段,未来的版本中可能在配置,容器镜像和程序入口等有所变化。
前提准备
- 一个分布式可运行的spark 2.3或者以上版本
- 一个正在运行的版本大于等于1.6的kubernetes集群,并且使用kuberctl可以访问集群。如果没有一个可以正常工作的集群,你可以使用minikube在本地机器启动一个测试集群。
- 建议使用最新版本的minikube,并且开启了DNS插件。
- 注意默认的minikube配置不足以运行spark应用,建议3个CPUs和4G内存去运行一个只有一个executor的spark应用。
- kubectl必须有合适的权限去列出、创建、编辑和删除集群中的pod,可以使用命令
kubectl auth can-i <list|create|edit|delete> pods验证。- 驱动程序pod所使用的service account必须可以拥有创建pod、服务和配置字典的权限。
- kubernetes集群中必须配置DNS插件。
工作原理
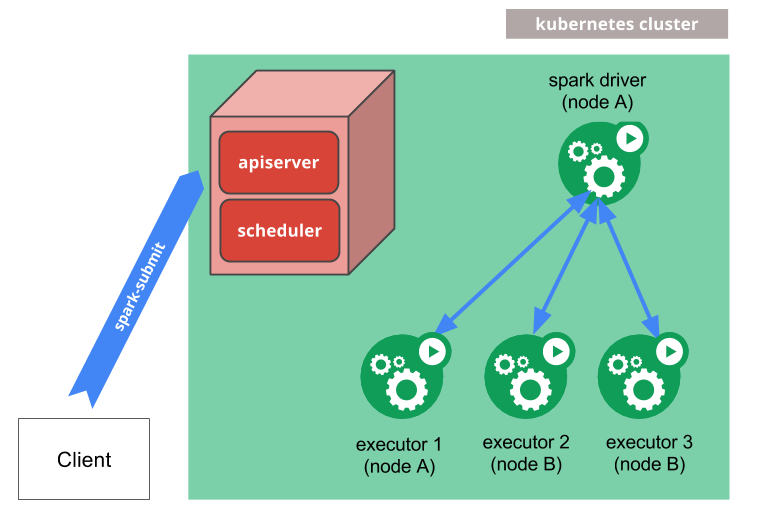
spark-submit能直接提交spark应用到kubernetes集群上,工作机制如下:
- spark以kubernetes pod的形式创建一个spark driver驱动程序。
- spark driver驱动程序创建executors,executors也是pod形式,driver可以和executor互相访问,并且执行应用代码。
- 当应用执行完成,executor pod就会终止并且销毁干净,但是driver驱动程序保留日志,在kubernetes api中显示为完成状态,直到最后的垃圾回收或者手动清理。
driver驱动程序显示为完成状态时,不会占用任何计算或者内存资源。
driver驱动程序和executor的pod调度都是由kubernetes控制,通过配置一个节点选择器(node selector)可以调度dirver和executor的pod到可用节点的一些子节点上面,在未来的版本中,可能会使用更多的调度策略,像节点和pod的关联性等。
提交应用到kubernetes
Docker镜像
kubernetes要求用户提供的镜像可以部署到pod容器里面,这个镜像构建在一个kubernetes支持的容器可运行环境,docker就是经常用来和kubernetes工作的一个容器可运行环境。spark从2.3版本开始支持使用Dockerfile,可以用来构建在kubernetes上可运行的容器环境或者定制符合个人需求的应用。Dockerfile在kubernetes/dockerfiles文件夹下面可以找到。
spark也附带了一个bin/docker-image-tool.sh脚本,可以用来构建和发布支持kubernetes的docker镜像。
./bin/docker-image-tool.sh -r <repo> -t my-tag build
./bin/docker-image-tool.sh -r <repo> -t my-tag push
集群模式
集群模式提交一个计算3.1415926的应用,
bin/spark-submit \
--master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=<spark-image> \
local:///path/to/examples.jar
spark master要么通过在 spark-submit 后面指定命令行参数 –master,要么在应用的配置中设置 spark.master,必须是 k8s://<api_server_url> 这样的格式。master字符串以 k8s:// 开头会 通过 api_server_url 连接到 API server,提交应用到kubernetes集群上面。如果没指定 HTTP 的协议,默认是 https。例如设置master为k8s://example.com:443 等同于设置为k8s://https://example.com:443,但是如果是使用一个不加密的其他端口,master应该设置为 k8s://http://example.com:8080。
在kubernetes部署模式中,spark应用的名称是通过spark.app.name或者是spark-submit命令的--name参数指定,这个名称也是在kubernnetes创建driver和executor的默认名称。因此,应用程序名称必须包含小写字母数字字符。必须以字母数字字符开始和结束。
如果你的kubernetes环境已经启动好了,可以通过kubectl cluster-info命令获取 apiserver的地址。
>: kubectl cluster-info
Kubernetes master is running at http://127.0.0.1:6443
在上面的示例中,这个kubernetes集群可以被spark-submit指定--master k8s://http://127.0.0.1:6443的参数提交应用,你也可用使用kubectl proxy启动一个API代理。如果这个代理启动在 localhost:8001,那么spark-submit的参数就是--master k8s://http://127.0.0.1:8001。最后注意,在上面计算3.1415926的示例中,我们指定的jar包是以 local:// 协议开头,这个地址就是example jar包在docker镜像中的路径。
依赖管理
如果你的应用程序的依赖都是在远程的HDFS或者HTTP服务器上,可以通过远程地址链接过来,也可以提前把依赖挂载进docker镜像中。这些依赖可以在 Dockerfile 中指定 local:// 或者设置 SPARK_EXTRA_CLASSPATH 环境变量添加到classpath中。
local://开头的路径指定的jar包都需要提前挂载到镜像中;目前还不支持来自提交客户端本地文件系统的应用程序依赖项。
使用远程依赖
当应用程序的依赖在远程的HDFS或者HTTP服务器上面,driver和executor需要一个init-container从远程上面下载这些依赖到本地。
这个init-container处理远程依赖,这些依赖通过 spark.jars(–jars)和 spark.files(–files)参数指定,包括主应用程序从远程下载。
bin/spark-submit \
--master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--jars https://path/to/dependency1.jar,https://path/to/dependency2.jar
--files hdfs://host:port/path/to/file1,hdfs://host:port/path/to/file2
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=<spark-image> \
https://path/to/examples.jar
保密字典管理
kubernetes的保密字典可以用来为spark程序提供访问加密服务的凭证。用户可以使用spark.kubernetes.driver.secrets.[SecretName]=<mount path>配置挂载保密字典到driver驱动程序的容器中,相同的spark.kubernetes.executor.secrets.[SecretName]=<mount path>可以挂载保密字典到executor容器中。挂载的保密字典需要和drvier、executor容器在相同的命名空间中。
如果使用了
init-container,任何挂载在driver容器中的保密字典,都会挂载到driver的init-container中,相同的executor也是一样的。
查看和调试
这里有几种不同的方式去查看一个运行状态或者完成状态的spark程序,监控应用执行进度和执行一些操作。
访问日志
日志可以通过kubernetes api或者kubectl命令来查看,当程序还在运行的时候,可以通过日志流查看。
kubectl -n=<namespace> logs -f <driver-pod-name>
日志也可以通过kubernetes dashboard查看。
访问驱动程序界面
和应用程序相关的web界面都可以在本地使用kubectl port-forward命令来查看。
kubectl port-forward <driver-pod-name> 4040:4040
调试
这里有几种失败的情况,如果kubernetes apiserver拒绝spark-submit的请求,或者连接被其他理由拒绝,说明本身提交的命令遇到了错误。如果是应用程序在运行过程中出现错误,最好的办法就是通过kubectl命令行查看。
可以用下面的命令获得关于驱动程序POD的调度决策的一些基本信息。
kubectl describe pod <spark-driver-pod>
如果应用程序遇到了运行时的错误,可以使用下面的命令进一步查看。
kubectl logs <spark-driver-pod>
executor容器的状态和日志查看方式和driver一样。最后删除driver容器将会清理整个spark应用程序,包括所有的executor、相关的服务等。这个driver容器可以想象成spark应用程序在kubernetes上的代理。
kubernetes特性
命名空间
kubernetes中有个namespace的概念,就是命名空间的意思,我们在其他的地方也可能听到过这个词,在多用户的时候可以通过资源配额去隔离不同用户的资源,提交spark任务的时候就需要通过spark.kubernetes.namespace的配置指定命名空间。
RBAC
如果kubernetes集群开启了RBAC的授权模式,用户为spark需要配置 RBAC 角色和 服务账号,这样spark程序才能访问到kubernetes apiserver。
spark driver驱动程序容器使用 服务账号 访问kubernetes apiserver,然后创建和查看executor容器。这个driver使用的 服务账号 必须有合适的权限保证driver完成自己的工作。具体的说就是,服务账号必须授予一个 role或者clusterrole的权限,保证driver可以创建容器和服务。如果没有指定服务账号,driver默认使用指定命名空间的default服务账号。
取决于kubernetes部署的版本不同,有的default服务账号可能没有创建容器和服务的权限,这个时候就需要用户自己自定义一个服务账号,然后授予正确的权限,通过下面的命令指定使用这个自定义的服务账号。
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark
创建一个名称为spark的服务账号。
kubectl create serviceaccount spark
授予服务账号一个 role或者clusterrole,就需要创建 RoleBinding或者ClusterRoleBinding,下面这个是在default命名空间中创建一个 edit ClusterRoleBinding,然后授予给spark服务账号。
kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=default
这里声明下,上面的命令中很多都是kubernetes的,需要对kubernetes有一定的了解。上面的命令很多都没有指定namespace,默认就是default,根据你自己的去指定–namespace=<your-namespace>
客户端模式
目前客户端模式不支持
未来的计划
在 apache-spark-on-k8s/spark 分支上正在孵化一些spark on kubernetes的特性,我们希望最后能在以后的版本中看到这些新特性。
- PySpark
- R
- executor动态伸缩
- 本地文件依赖管理
- spark应用程序管理
- 任务队列和资源管理
配置
配置太多,参考文档